Significance of Bioinformatics in Precision Oncology
Pravitha Kasu Sivanandan, Bioinformatician, MVR Cancer Centre & Research Institute
This article explores the profound impact of bioinformatics in the realm of precision oncology, revolutionising the understanding, diagnosis, and treatment of cancer. Bioinformatics, a multidisciplinary field, bridges the gap between vast biological datasets and meaningful insights, enabling personalised therapies and groundbreaking discoveries. However, challenges in data integrity, reproducibility, and infrastructure must be overcome to fully realise it’s potential. Bioinformatics stands as a beacon of hope, ushering in an era where cancer is decoded at its molecular core, promising improved patient outcomes and a brighter future in the fight against this formidable disease.
Introduction
In an era where medical science is advancing at an unprecedented pace, the integration of bioinformatics has emerged as a game-changer, offering new avenues for understanding, diagnosing, and treating cancer.
Bioinformatics: Bridging the Gap
Bioinformatics is a multidisciplinary field that harnesses the power of information technology, mathematics, statistics, machine learning, and even quantum physics to solve complex biological problems. Its primary goal is to make sense of vast biological datasets by providing algorithms and methods for data cataloging, visualisation, annotation, interpretation, and more. With the advent of Next-Generation Sequencing (NGS) technologies, the field has witnessed an explosion of computational tools and databases that have accelerated research in unprecedented ways.
In the age of information and the internet, data accessibility is no longer the primary hurdle. The challenge now lies in deciphering and making sense of the colossal datasets generated. This is where bioinformatics steps in, offering a standardised approach to analyse and extract meaningful insights, be it in understanding website traffic statistics or decoding the human genome. Ultimately, bioinformatics aims to unravel the complexities of human biology and health through the analysis of genomic data.
The Evolving Landscape of Biological Data
Over the past decade, the definition of "biological data" has undergone a profound transformation, shifting from small datasets to massive collections comprising millions of entities, including genes, protein isoforms, alternative splicing variations, and CpG islands. This exponential growth has led to the development of an ever-expanding array of bioinformatics tools. As new tools and methodologies emerge, they are swiftly accompanied by fresh sources of data, making the field dynamic and continually evolving.
Precision Oncology and Bioinformatics
Precision oncology represents a paradigm shift in cancer treatment, and bioinformatics is at its core (Figure.1). This approach leverages multi-omics data to identify underlying genetic variants driving diseases like cancer. Bioinformatics tools, empowered by high computing capabilities, are essential for analysing complex biological datasets. Machine learning algorithms, a vital component of bioinformatics, enable applications in diagnosis, disease prognosis, individualised care, predicting medication responses, and drug repurposing.
The promise of multi-omics techniques lies in improving diagnosis, prognosis, and personalised care. To fulfill this promise, bioinformatics tools capable of managing, integrating, and analysing extensive and intricate datasets are imperative. Thanks to advancements in next-generation sequencing (NGS), major cancer centers worldwide can now offer personalised oncology based on the molecular profiles of tumors. Genetic aberrations such as single-nucleotide variations (SNVs), copy number variants (CNVs), insertions and deletions (indels), structural variants (SVs), and gene fusions are profiled to match potential treatments.
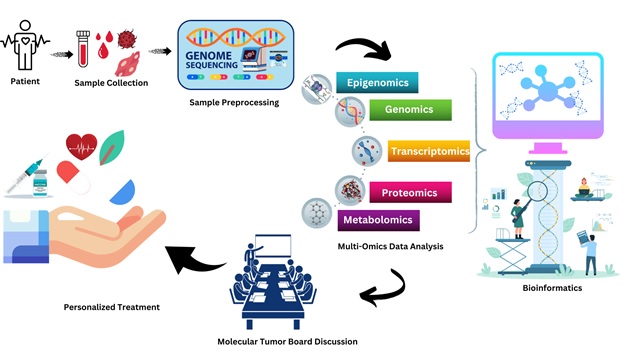
Figure.1. The function of bioinformatics in precision oncology.
Discoveries in Precision Oncology through Bioinformatics
Bioinformatics has played a pivotal role in uncovering groundbreaking discoveries in precision oncology. By leveraging computational tools and advanced data analysis techniques, researchers have made significant strides in understanding the molecular basis of cancer, identifying targeted therapies, and personalising treatment approaches. Here are a few notable examples of discoveries that highlight the significance of bioinformatics in precision oncology:
Targeted Therapy in EGFR-Mutated Lung Cancer
Bioinformatics analyses of genomic data have led to the identification of specific mutations, such as those in the epidermal growth factor receptor (EGFR) gene, in non-small cell lung cancer (NSCLC) patients. These bioinformatics-driven discoveries have enabled the development of targeted therapies like gefitinib and erlotinib. Patients with EGFR mutations can now receive treatments tailored to their genetic profiles, resulting in improved outcomes and fewer side effects compared to traditional chemotherapy.
BRCA1 and BRCA2 Mutations in Breast and Ovarian Cancer
Bioinformatics has played a crucial role in identifying individuals with mutations in the BRCA1 and BRCA2 genes, which significantly increase the risk of developing breast and ovarian cancer. By analysing large-scale genomic datasets, bioinformaticians can pinpoint these genetic alterations. As a result, individuals at high risk can undergo preventive measures, such as prophylactic surgeries or enhanced screening, to detect cancer at an early and treatable stage.
Immunotherapy Response Prediction
Immunotherapy has revolutionised cancer treatment, but not all patients respond equally. Bioinformatics-based analyses of tumor microenvironments, immune cell infiltration, and gene expression patterns have enabled the development of predictive models for immunotherapy response. These models help oncologists identify patients who are most likely to benefit from immunotherapies, such as checkpoint inhibitors, sparing others from potential side effects and treatment costs.
Tumor Evolution and Drug Resistance
Bioinformatics tools have shed light on the complex evolution of tumors and the emergence of drug resistance. By tracking genetic changes over time through longitudinal genomic data analysis, researchers can identify the mechanisms underlying resistance to targeted therapies. This knowledge guides the development of combination therapies and treatment strategies to overcome resistance and prolong patient survival.
Pharmacogenomics and Drug Personalisation
Pharmacogenomic studies, driven by bioinformatics, have revealed genetic variations that influence an individual's response to cancer drugs. By analysing patient genetic profiles, oncologists can tailor treatment plans to maximise efficacy and minimise adverse effects. For example, bioinformatics can identify patients with genetic variants that affect drug metabolism, allowing for dose adjustments or alternative drug choices.
Challenges in Implementing Bioinformatics in Precision Oncology
Despite its tremendous potential, the integration of bioinformatics into precision oncology faces significant challenges. Healthcare systems, both public and private, are inundated with a deluge of data, including patient genetic information, medical records, clinical trial results, and diagnostic imaging. Traditional database systems struggle to handle the explosive growth in unstructured data volume and velocity.
Precision medicine, like any technological advancement, requires time for adaptation. Its successful integration into healthcare systems hinges on resolving organisational, ethical, and regulatory issues, bridging evidence-generation gaps, addressing infrastructure and data-sharing concerns, and accelerating the incorporation of genomic data into clinical care and research. Additionally, economic considerations must be taken into account.
Before fully harnessing the potential of bioinformatics in precision oncology, need to establish legislation to protect genomic data, create decision-making tools, prepare workgroups, and build trust and confidence among patients and clinicians alike.
Ensuring Data Integrity and Reproducibility in Molecular Tumor Boards(MTBs)
High-throughput Next-Generation Sequencing (NGS) has revolutionised the molecular probing of tumors, offering a time- and cost-effective approach. However, the vast size of sequencing data and the presence of various sources of variation, such as amplification and sequencing errors, pose significant challenges for accurate analysis. In the context of Molecular Tumor Boards (MTBs), where treatment decisions based on mutation calls can have life-altering consequences, adherence to strict standards is paramount.
Distinguishing Signal from Noise
The first and foremost concern in NGS data analysis is distinguishing true biological signals from experimental noise and technical artifacts. Treatment decisions must rely on validated biological alterations, ensuring that patients are not subject to incorrect recommendations. To achieve this, it is imperative to employ robust computational data analysis pipelines that cover the entire data processing journey, from primary read analysis to clinical reporting. These pipelines should undergo rigorous evaluation under defined conditions, mirroring real-world scenarios. Furthermore, mutation calls should come with a confidence estimate to convey the reliability of results.
Ensuring Reproducibility
Reproducibility is a cornerstone of reliable NGS data analysis. Several technical prerequisites are essential to meet this requirement. Controlling random seeds for randomised steps is crucial, and thorough documentation of each pipeline step is mandatory. This documentation should encompass details of the tools used, their versions, and parameter settings. It extends to the reference genome used, as different versions can lead to confusion and discrepancies. Moreover, genomic studies may encounter incidental variants unrelated to cancer, necessitating a clear strategy for their reporting.
Transparency and Traceability
Transparency is essential in ensuring the traceability of all results generated by the bioinformatics pipeline. It should be possible to trace back critical mutation calls, allowing for manual assessment and validation before recommending treatment. This requires a comprehensive description of file generation and dependencies for each step in the pipeline. Additionally, in the context of MTBs, where critical decisions must be made urgently, clear strategies for reporting and handling incidental findings are vital, given their ethical implications.
Challenges in Computational Infrastructure
Comprehensive clinical datasets in MTBs, coupled with the urgency of patient cases, present challenging technical prerequisites for computational infrastructure and data analysis software. The size, sensitivity, and complexity of these datasets demand robust and high-performance computational solutions to ensure timely and accurate decision-making.
In conclusion, maintaining data integrity, reproducibility, and transparency in NGS data analysis within the context of MTBs is of paramount importance. Adhering to stringent standards and leveraging robust computational pipelines are essential steps in ensuring that treatment decisions are based on sound biological evidence, ultimately improving patient outcomes.
Conclusion
This article explored the transformative role of bioinformatics in precision oncology—a field that promises to revolutionise cancer diagnosis and treatment. Bioinformatics, powered by cutting-edge technology and multidisciplinary expertise, has become the linchpin for deciphering the complexities of cancer biology and tailoring treatments to individual patients.
Bioinformatics bridges the gap between vast biological datasets and meaningful insights, enabling researchers and clinicians to make informed decisions. Its role in processing Next-Generation Sequencing (NGS) data has opened doors to targeted therapies, immunotherapy response prediction, and the understanding of tumor evolution and drug resistance.
However, integrating bioinformatics into precision oncology is not without its challenges. The sheer volume and complexity of data, coupled with the need for robust computational pipelines, pose technical hurdles. Ensuring data integrity, reproducibility, and transparency is essential, particularly in the context of Molecular Tumor Boards (MTBs), where treatment decisions can be life-altering.
The promise of bioinformatics in precision oncology is immense, but it necessitates the resolution of organisational, ethical, and regulatory issues. Genomic data protection, decision-making tools, workgroup preparedness, and building trust among patients and clinicians are all vital components of this journey.
As medical science continues to advance, bioinformatics remains at the forefront of precision oncology, offering hope for improved patient outcomes, reduced treatment-related toxicity, and a brighter future in the fight against cancer. The synergy between biology and information technology is propelling us into an era where cancer can be understood at its molecular core, leading to more effective treatments and, ultimately, better lives for patients.
References
- Jochen Singer, Anja Irmisch, Hans-Joachim Ruscheweyh, Franziska Singer, Nora C Toussaint, Mitchell P Levesque, Daniel J Stekhoven, Niko Beerenwinkel, Bioinformatics for precision oncology, Briefings in Bioinformatics, Volume 20, Issue 3, May 2019, Pages 778–788, https://doi.org/10.1093/bib/bbx143
- Singer, Jochen et al. “Bioinformatics for precision oncology.” Briefings in bioinformatics vol. 20,3 (2019): 778-788. doi:10.1093/bib/bbx143
- Canzoneri R, Lacunza E, Abba MC. Genomics and bioinformatics as pillars of precision medicine in oncology. Medicina (B Aires). 2019;79(Spec 6/1):587-592. English. PMID: 31864231.
- Jäger N. Bioinformatics workflows for clinical applications in precision oncology. Semin Cancer Biol. 2022 Sep;84:103-112. doi: 10.1016/j.semcancer.2020.12.020. Epub 2021 Jan 18. PMID: 33476720.
- Yudong Cai, Tao Huang, Jialiang Yang, "Applications of Bioinformatics and Systems Biology in Precision Medicine and Immunooncology", BioMed Research International, vol. 2018, Article ID 1427978, 2 pages, 2018. https://doi.org/10.1155/2018/1427978
- Yang, Hsih-Te et al. “Precision oncology: lessons learned and challenges for the future.” Cancer management and research vol. 11 7525-7536. 7 Aug. 2019, doi:10.2147/CMAR.S201326
- Yu, Kun-Hsing, and Michael Snyder. “Omics Profiling in Precision Oncology.” Molecular & cellular proteomics : MCP vol. 15,8 (2016): 2525-36. doi:10.1074/mcp.O116.059253
- Chen, C, Wang, J, Pan, D, et al. Applications of multi-omics analysis in human diseases. MedComm. 2023; 4:e315. https://doi.org/10.1002/mco2.315
Pravitha Kasu Sivanandan holds an MSc in Bioinformatics from Bharathiyar University, India, and works as a Bioinformatician at MVR Cancer Centre & Research Institute. She specializes in multi-omics data analysis, focusing on stratified healthcare. She focuses on potential of bioinformatics in precision oncology. Pravitha is also an Associate Member of AACR.









