Designing efficient therapies to modulate epigenetics is a major challenge of precision medicine. Cells are composed by a plethora of molecular species subjected to randomness and multiple time scales, while dynamically interacting with environment. Application of mathematical methods for control of processes helps on the development of personalised treatment strategies.
Despite all recent advances of molecular biology and imaging techniques, treatment designs based on pharmaceuticals still need enhancement to improve prognostics of patients while reducing the severity of side effects. The development of DNA sequencing techniques enabled an unprecedented increase of our understanding of genetic diseases such as cancer [1]. Cancer sub-types classification based on specific mutations, such as the mutation of Epidermal Growth Factor Receptor (EGFR) gene related to lung cancer, increased prognostic accuracy while providing the opportunity for early interventions. In some cases, that may even result in pre-disease surgical intervention as it may happen when mutations are detected in BRCA1 and BRCA2 genes as those may be key factors underpinning emergence of breast cancer. Because of its stationary character, however, knowledge of the genome of a patient is not sufficient to understand when or how a genetic disease manifests. The effects resulting from interaction with environmental factors and the dynamic character of expression of genetic information require the use of an additional conceptual framework. For that, experimentally validated mathematical models may play an important role.
The post-genomic age is characterised by the necessity of knowing not only which genes are inside a cell but also when, where and how many products are synthesised from those genes. That propelled the field of epigenetics and opened a new avenue for designers of treatment strategies. As our understanding of epigenetics advances, treatment may be designed to exploit the coordinated dynamics of a plethora of chemical components interacting inside the cell. A major goal of such an epigenetic engineering is to reprogram the cellular behaviour to increase chances of treatment success. That reprogramming is achieved by the proper manipulation of either gene networks or signalling pathways by means of genetic techniques that enable one to change the DNA or inputting chemicals that intervene on the amounts of products synthesized from a set of genes.
In its simplest representation, a gene network is a set of genes and their products, namely proteins, also termed transcription factors (TF) because of their biological function. TFs bind to the regulatory regions of a gene and either stimulate or repress its expression. If the transcription factor from a gene A binds to the regulatory region of gene B to stimulate or repress its expression, we say that genes A and B interact. The reverse interaction may also happen. One may affect the dynamics of a gene network, and hence, the amounts of products that it generates, by modulating the numbers of specific TFs. This modulation can be done by means of specific chemical agents driving the activity of signalling pathways that activate some TFs of a gene network governing a specific cellular process. This sort of reprogramming is achieved by target treatments, such as it happens in cancer [2].
EPIGENETICS is the discipline dedicated to the investigation of how the expression of a genome is governed by the multiple environmental inputs that affect the cell behaviour.
GENE can be considered as a DNA sequence composed by the region encoding its protein and the regions to which regulatory components bind to modulate the amounts of products expressed from a gene.
Gene editing provides an additional opportunity for reprogramming cellular dynamics. One may inject Plasmids which will interact with the intracellular machinery participating in gene expression. Alternatively, one may use CRISPR to insert a specific sequence in the cellular DNA. Either the plasmid or the inserted sequence will drive the expression of transcription factors responsible for modulating the expression of specific gene networks so that the internal state of a cell may be redirected towards a condition favouring a patient. Note, however, that one designing treatment strategies based on re-modulation of gene networks may need to take into consideration a few intrinsic features of the intracellular environment. Here we consider the unavoidable stochasticity and multiple time scales of the internal processes of the cell.
Randomness of intracellular biochemical processes was predicted a long time ago by Max Delbruck. That happens because of the small number of copies of reactants interacting inside the cell. Hence, the time interval between subsequent reactions vary and, that causes a more proeminent variability on the number of reaction products. Such a randomness introduces an additional challenge for engineering the epigenetics of a cell, since predictability of stochastic processes can only be done in terms of probabilities. Hence, treatment designers will need to incorporate the probabilistic thinking to their conceptual framework.
Besides, the processes taking place inside the cell have a multiplicity of characteristic time-scales. That sets an additional challenge, because one may aim to design a treatment in which the drug and the chemical process affected by it have an optimal coupling. However, either the drugs and the cellular processes have their own characteristic time scales. Therefore, the time of response of each combination of drug and chemical process will vary accordingly.
EXAMPLES OF GENE NETWORKS
Externally regulated gene is a gene which expression is regulated by TF encoded on other genes.
Self-regulating gene is a gene which expression is regulated, positively or negatively, by the TF that it encodes.
Repressilator is composed of two genes, A and B, and the TF from one gene represses the expression of the other.
This biological picture illustrates some complex challenges to be faced by those aiming to design new treatment strategies based on genetics or epigenetics tools. Experimental methods have been employed with success on treatment design, but precision medicine will also benefit from the use of mathematical and computational tools. These enable the construction of testable quantitative models aimed to help experimentalists to reduce their set of hypothesis to be tested at the bench.
Computational tools, mainly devoted to data analysis, may enable the discovery of unexpected patterns on the dynamics of biological systems. One example is the analysis of gene expression in the cells of a tissue under healthy or disease condition. Application of bioinformatics methods on online data revealed that variability in gene expression levels, measured by variance, increases during disease. Indeed, a major feature of tumours is their heterogeneity, caused by re-modulation of gene networks towards differential expression levels that are still capable of holding the viability of cells [3].
Besides insights about the biology of cells, the results of data analysis may also be summarised in effective mathematical models which may play a descriptive role at first and, eventually, provide testable predictions. The latter is a more ambitious goal of theoreticians as it means a deeper understanding of the workings of biological systems. To be considered as predictive, however, a model is subjected to multiple tests designed to provide validation. As those models "pass the tests" they motivate insights about the functioning of biological systems that can be increasingly useful.
One possible approach for building such effective models is to consider the building blocks (or elementary processes) composing a given system. One example is the functioning of an externally regulated gene. In a human, regulation of gene expression is a complex process which is hard to assess experimentally. Thus, one might use a mathematical model to aid on the understanding of the dynamics of an eukaryotic gene.
For simplicity, we take the externally regulated gene. As a first approximation, we describe it as a source that switches between ON and OFF states. When the source is ON, the gene products are synthesised at a rate that depends on specific characteristics of the gene such as its affinities to the transcriptional machinery. The rate of the switching of the source may be represented by constants that reflect the state of the regulatory region of the gene during some small time interval. Additionally, the gene products also decay. Hence, the state of this system is determined by the source being ON or OFF and by the number of gene products being 0, 1, 2, and so on.
PLASMID is a small DNA commonly found in bacteria, in circular form. It is transcribed independently of the DNA of the chromosomes. Currently, techniques allow the synthesis of artificial plasmids to serve as vectors that carry genes of interest to be expressed in a particular cells, which may be prokaryotic or eukaryotic.
CRISPR (clustered regularly interspaced short palindromic repeats) is the term used for a set of stretches of DNA repeated in a region of the strand, which were first identified as an antiviral defense mechanism in bacteria. The association of CRISPR with DNA-cleaving enzymes, such as Cas9, allowed the creation of a gene editing technique in specific regions of the DNA strand.
MATHEMATICAL MODELS: we consider as a mathematical model a system which state is described by some set of equations built to govern the dynamic behaviour of the dependent variables of the system. Typically, the independent variables of those systems are time and position of a given entity which is aimed to be described by the mathematical model.
STOCHASTIC MODELS: mathematical models may be divided in deterministic and stochastic. A model is called deterministic if one may predict its state at a future time once the initial conditions of the system are provided. Alternatively, if the future state of a system, provided its initial conditions, is predicted accordingly with probabilities, then we have a stochastic model
The cartoon in Figure 1 is an effective description of the functioning of an externally regulated gene. It indicates the existence of a combination of four parameters, each related to one process participating on the regulated expression of a gene. Additionally, one needs to consider the randomness of the intracellular processes. That leads to the necessity of building a stochastic model to govern the evolution of the probabilities of finding the gene in a given state. One possible model has been around for a few decades and is fully solvable [4,5], which means that one may get explicit mathematical formulas to express the probabilities of finding the gene in a given state either at the timedependent and stationary regimes. After obtaining the time-dependent solutions one notes the existence of two time-scales governing the dynamics of expression of the externally regulated gene: the first is associated with the i. synthesis and degradation of gene products which is the degradation rate; the second is related to the ii. promoter switching between ON and OFF states and is given in terms of the average frequence for the gene to complete a switching cycle between states ON/OFF/ON (or vice-versa).
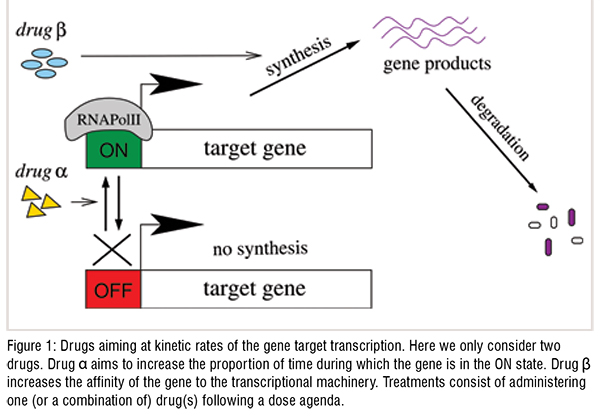
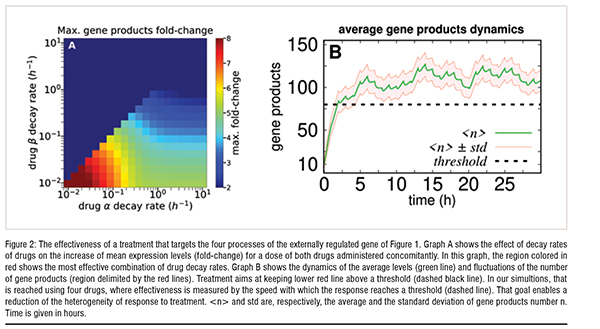
A next step on the modelling procedure is to perform an inference of the values of the parameters of the model for a specific gene. The estimation is based on experimental data and can be considered as a challenge per se. First one must build a system which gene expression dynamics can be monitored. Molecular biological techniques recently developed enabled one to introduce fluorescent proteins which can be imaged by means of confocal microscopy. Those techniques are sufficiently advanced to enable one to molecularly engineer a large set of potentially useful genes. Hence, the selection of the gene may be mostly guided by biological or biomedical criteria such as its potential role as a master regulator in a cancer cell.
Once a model system is devised, it may be used for benchmarking treatment designs by monitoring how it affects the expression of a master regulatory gene. One may combine both the experimental data and the mathematical model for parameter values inference. Since the mathematical model is fully solvable, one may establish the dynamics of the average number of transcripts and their fluctuations. Moreover, in disease state, such as cancer, the patterns of expression of master regulatory genes may be changed. Hence, a fair treatment goal is to reestablish gene expression levels towards those found in a healthy state. In the case of cancer, that may imply on the need of administration of multiple doses to ensure that the expression does not return to disease related levels.
TIME-DEPENDENT AND STATIONARY REGIMES. In the time-dependent regime, the dependent variables governed by the system of equations representing a given system do change with time. In the stationary regime, the variables stop changing. A warning is necessary: in the stochastic description a system is in the stationary regime if the probabilities of finding the system in each state do not change. However, it does not mean that the state of the system is constant. One example is an unbiased coin being flipped: the probabilities of finding the head or tail are constant but at each toss the face up may change with probability 0.5.
The above goal of maintaining expression levels, and fluctuations, of specific genes within specific ranges of values can be approached by means of control theory. This mathematical formulation enables one to dynamically adapt drug dosage to ensure that expression levels and fluctuations remain within the necessary range [5]. That formulation must be fully tested in laboratory before it can become available for treatment. However, it is a promising direction for further developing gene therapies or treatment designs aiming at modulating gene networks dynamics. Once a control model for regulation of gene expression becomes fully validated, one may even consider the possibility of designing drug delivery machines that would control drug dosage automatically based on some set of data about a specific process taking place in a tissue.
Bibliography
[1] Mukherjee, S. The emperor of all maladies: a biography of cancer. 2011. Harper Collins Ed.
[2] Yesilkanal, A.E.; Yang, D.; Valdespino, A.; Tiwari, P.; Sabino, A.U.; Nguyen, L.C.;Lee, J.; Xie, X.H.; Sun, S.; Dann, C.; et al. Limited inhibition of multiple nodes in a driver network blocks metastasis. eLife 2021, 10, e59696. doi:10.7554/elife.59696.
[3] Zaravinos, A.; Bonavida, B.; Chatzaki, E.; Baritaki, S. RKIP: A Key Regulator in Tumor Metastasis Initiation and Resistance to Apoptosis: Therapeutic Targeting and Impact. Cancers 2018, 10, 287. doi:10.3390/cancers10090287.
[4] Peccoud, J.; Ycart, B. Markovian modelling of gene product synthesis. Theor. Popul. Biol. 1995, 48, 222–234. doi:10.1006/tpbi.1995.1027.
[5] Giovanini, G.; Barros, L. R. C.; Gama, L. R.; Tortelli Jr, T. C; Ramos, A. F. A Stochastic Binary Model for the Regulation of Gene Expression to Investigate Responses to Gene Therapy. Cancers, 2022, 14, 633. doi:10.3390/cancers14030633.

Alexandre Ferreira Ramos (Assistant Professor, University of São Paulo, Brazil) coordinates the Applied Mathematics and Biological Physics laboratory (AMPhyBio). Investigates biological and biomedical phenomena using group and graph theory, stochastic processes, statistics, simulations, digital image analysis, machine learning, and high performance computing. Control theory-based treatment design is a next frontier of investigation

Guilherme Giovanini holds a degree in biological physics and a master degree in modeling complex systems (University of São Paulo, Brazil). Under the supervision of Prof. Alexandre Ramos, he studies quantitative models for designing treatments aiming the expression of target genes in cance













